Software ported to CUDA/GPU
Our solution
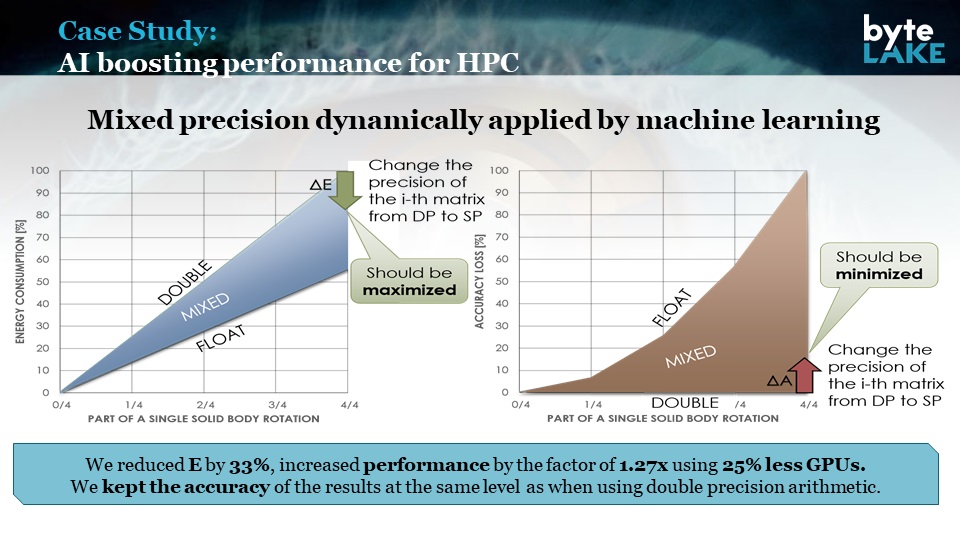
In this case, we ported software to CUDA environment (CPU+GPU) and applied a mixed precision arithmetic to optimize it. That allowed us to enforce that a part of operations was performed in a single precision (32-bits) and the remaining set in double precision (64-bits).
Results
We reduced the energy consumption of the algorithm by 33%, increased performance by the factor of 1.27x using 25% less GPUs and keeping the accuracy of the results.
Benefits for the customer
- Software ported from traditional architectures (mainly CPU-based) to CUDA environment
- Significantly improved performance of the software, utilizing fully the underlying hardware
- Cost reduction as the resulting software required 25% less GPUs
- that short term could lead to savings as less hardware was required to run the simulation (no need to upgrade everything)
- long term, however, that enabled the customer to do more with the existing hardware
- also the solution enabled better planning in terms of workload requirements
Details
- A single simulation needed more than 〖10〗^13 operations. We suspected that not all of them needed a double precision arithmetic to preserve the same simulation accuracy.
- We used an unsupervised learning to estimate the correlation between the precision of each matrix with data and their influence on criteria like energy and accuracy of results).
- During the dynamic and short training stage we evaluated a set of operations that could be performed in a single precision without the loss in accuracy of the algorithm results.
- Technical highlights: C++, CUDA, MPI, OpenMP
- Find out more in our presentation on SlideShare
- Explore more about our expertise in NVIDIA technologies