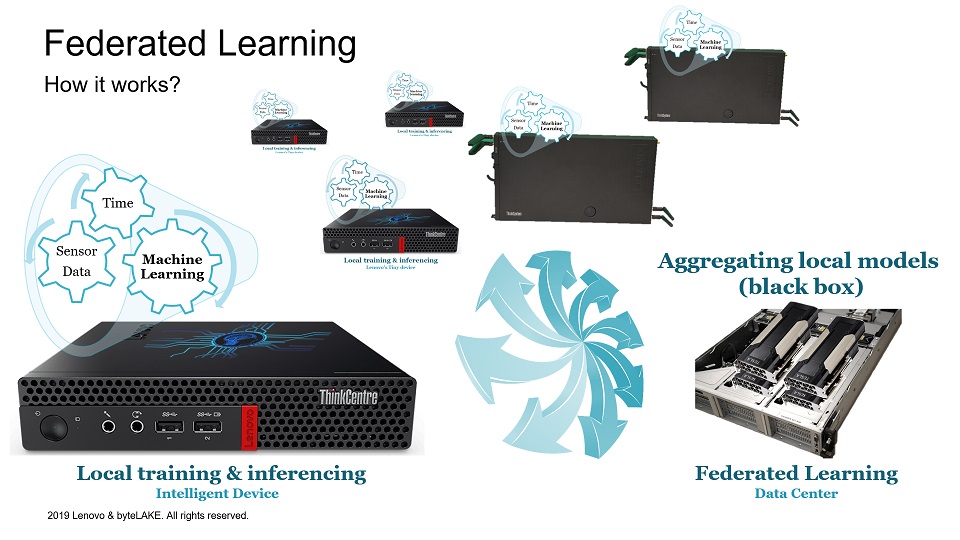
Federated Learning
- Federated Learning moves AI computing to the edge to leverage on locally trained models
- Ensures privacy as models get trained without accessing the raw data directly
- Also, data stays locally on edge and only models travel beyond
Federated Learning is a machine learning setting that allows us to create a model based on a number of other local models (not raw data). The local models are usually distributed across the network of independent clients.
The clients are very often accessible thru unreliable or low throughput networks. Thus it is in many cases hard or almost impossible to download their raw data. In other cases, access to the client’s raw data might be limited by various regulations, policies etc. Hence we can follow a path of processing the raw data directly on such clients and producing a number of distributed machine learning models. Then we can aggregate them with a help of federated learning. Lastly, the aggregated model can be distributed back to the clients in a form of an update.

Federated Learning works in a loop:
- clients: run machine learning to process raw data and produce local models
- server: collects local models, aggregates them and sends back an update to clients
- clients: receive an update and include it in another round of training, producing new local models.
In essence, the key thing is that we do not have to share the data. We rather share models and aggregate them.